Historical context
Community ecology focuses on quantifying relationships between species, in time and- or space. In the beginning of the 20th century, this took the form of simple, descriptive, statistics or visualizations of multivariate data (i.e., the presence or abundance of species measured at sites). Over the years, there was a push for a more quantitative way to summarize such data. Because computer power was limited, relative simple methods had to be employed. Ordination methods such as Principal Component Analysis and Correspondence Analysis have now been used in community ecology for almost 100 years. Although they are easy to implement thanks to improvements in software packages, and computationally cheap, inferring ecological relationships from their results remains an advanced skill to acquire. There are also other methods that are still actively implemented in community ecology, such as non-metric Multidmensional Scaling. Although NMDS was considered computationally intensive, once upon a time, present-day computing power has largely made those kind of arguments obsolete. Although these established methods are decades old, they still function well, and still have an important role in present-day community ecology (and in other subfields of ecology too). Each method has been extensively studied, and their deficits (the things they do not do well) are well known. For example, PCA only works well for ecological data that come from "a short gradient". If you imagine a tree species occurring along a moisture gradient, we can think of this tree having a preferred place along that gradient. Some species prefer high soil moisture, and others low soil moisture. Its abundance at different places along the soil moisture gradient is a reflection of that preference. PCA functions well if applied to data observed at only a small part of that gradient, say at different environments with high soil moisture. CA and NMDS have other deficits. CA often constructs poor looking ordinations, because of various assumptions it makes, and NMDS does not do constrained ordination and has only limited tools available for inference. All of these have led to the development of contemporary methods for analysing data on ecological communities, which are covered in this summer school.
Methodological frameworks
Fast forwarding to the 21st century, many more methods exist for analysing data on ecological communities than was the case in the 20th century. Statisticians have been developing methods for decades, including but not limited to, ordination methods. All of these methods are a kind of statistical model, and usually in one way or another related to the Generalised Linear Model. In this summer school, we will focus on teaching participants about Generalised Linear Models, Vector Generalised Linear Models (the equivalent of GLMs for data of multiple species), Generalized Linear Mixed-effects Models (and their multispecies equivalent), and Generalized Linear Latent Variable Models (GLLVM). There are other methods for multispecies data that are not covered here, but these four frameworks should cover most needs of community ecologists, and even for ecologists in other disciplines (such as quantitative genetics). Unlike the aforementioned ordination methods, each of these frameworks are applicable to all possible data types that can be collected in community ecology; presence-absence, biomass, counts, or otherwise. As we will cover in the summer school, this just requires a change in the response distribution.
Generalised Linear Models
Generalised Linear Models are an incredibly flexible framework for modeling all kinds of data. In our context, GLMs are best applied to data for a single species due to some of the assumptions that they make. Not to worry, those assumptions can be relaxed! GLMs are a good place to start, but generally not the best tool to analyse multivariate data. Vector GLMs relax a critical assumption (that of equal dispersion for all observations), and Vector GLMMs generalise GLMMs as VGLMs generalise GLMs.
Joint Species Distribution Modeling
A popular modeling framework in community ecology, is Joint Species Distribution Modeling (JSDM). JSDMs are a class of multispecies models for presence-absence data, uniquely suited for representing co-occurrence patterns (i.e., finding out why, or where, species occur together). These usually have a large-scale focus (e.g., country-level or coarser), but are not limited to such scales. More generally, models will be covered in the summer school also for other data types beyond presence-absence, as part of the GLLVM framework. JSDMs are a type of GLLVM, implemented using latent variables. Latent variables are kind of like unmeasured gradients, and are the component of the model that help to better incorporate co-occurrence patterns of species that are unmeasured. Although this technically makes them a kind of VGLMM too, "JSDM" is a more popular choice of terminology.
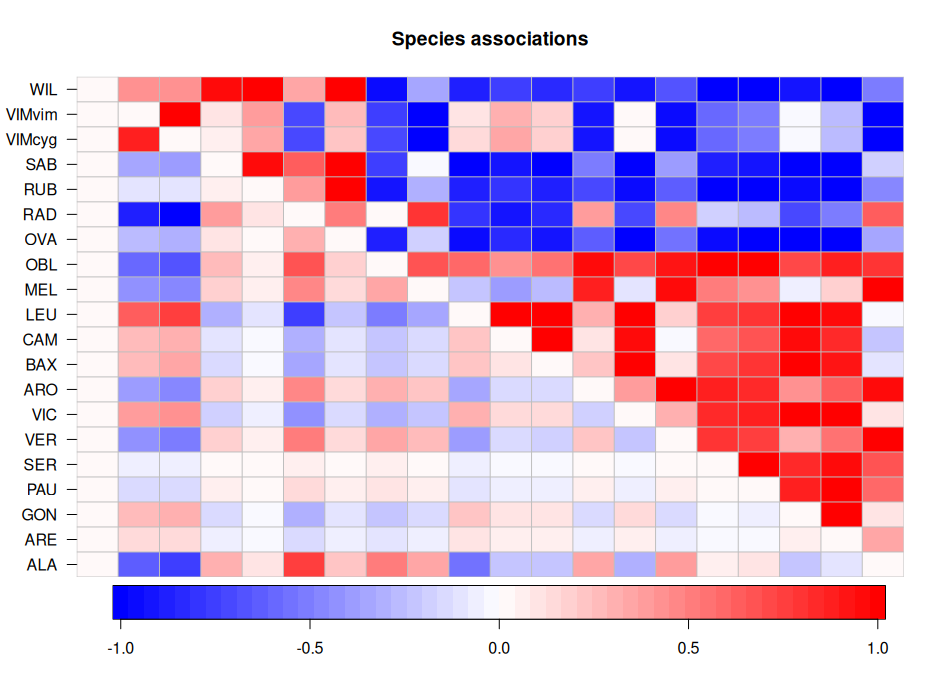
Model-based ordination
Model-based ordination is synonymous to GLLVMs. Unlike in JSDMs, species co-occurrence patterns do not necessarily take the forefront, but are rather in the back of our heads when applying the models. Instead, we focus on finding or representing latent variables (i.e., ordination axes) that underlay our ecological community. In this, they are akin to the ordination methods already widely applied in community ecology; PCA, CA, NMDS and others. However, GLLVMs are unique in their ability to make great ordinations, and the tools that are available to better understand ecological communities. They are best thought of a combination of GLM(M)s and more typical ordination methods.
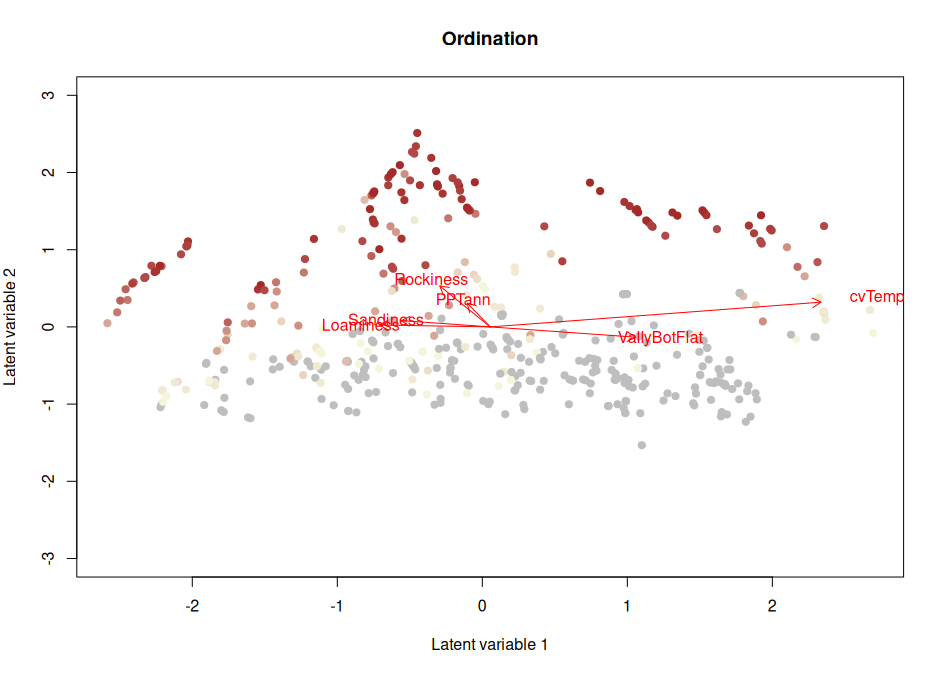
But what about the ecology?
All this talk about methods might make you wonder whether or not we will be doing any ecology in the summer school. The summer school will aim to teach you methods that can help you better understand your ecological communities, and teach you tools for more advanced inference. We will teach you how to deal with things such as nested study designs or rare species in multivariate data, finding relevant environmental variables, or how to deal with statistical uncertainty. We will demonstrate the tools with example data, and interpret the results to the best of our ability. Of course, we can think with you about the interpretation of your results, but ultimately you know the system that your data was collected in better than we do. The models and tools can help to lift your ecological inference to new heights, but ultimately it your understanding of ecology, and the research questions that you have formulated, which should lead your study.